简介
2019.01.25 deepmind公布了最新StarCraftII Agent AlphaStar,对职业选手Mana和TLO的战绩为10胜1负。目前Agent只支持使用Protoss族,但是架构支持所有种族无限制对战
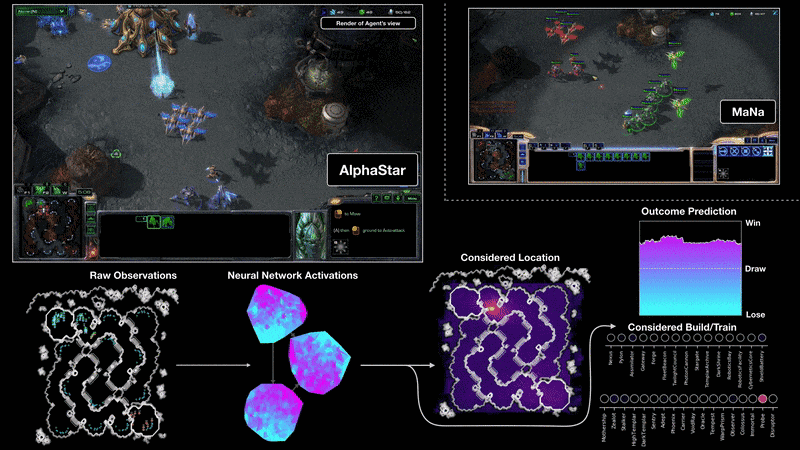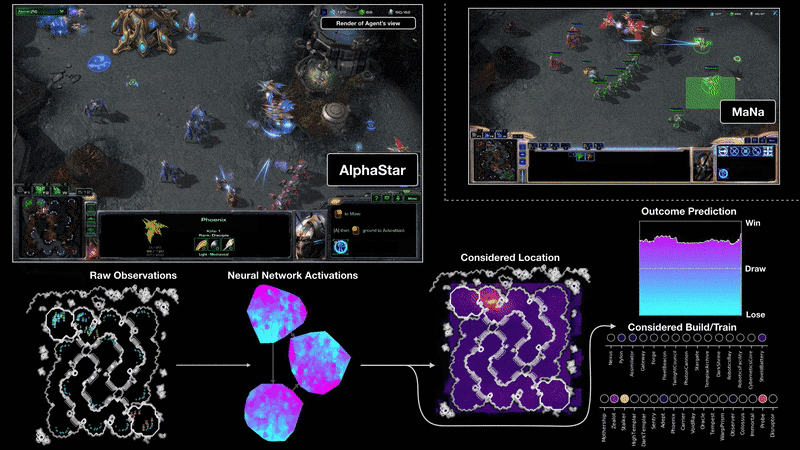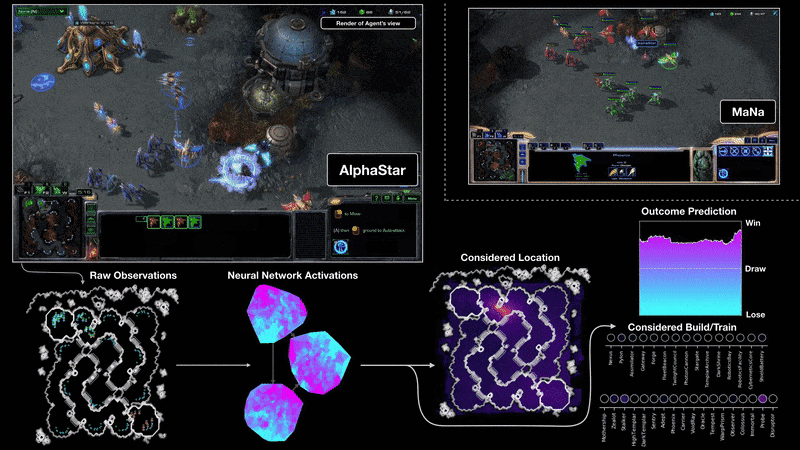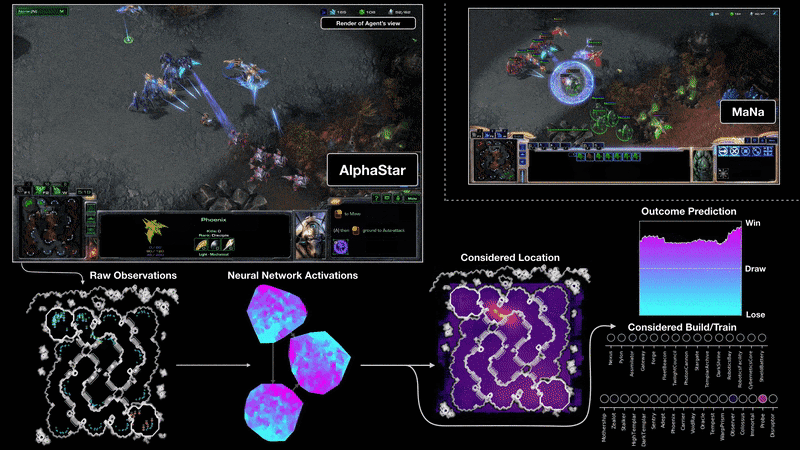
训练过程
Agent训练基于PySC2接口
对单元采用transformer torso + LSTM + auto-regressive policy head (pointer net) + centralised value baseline (a3c)
multi-agent学习算法
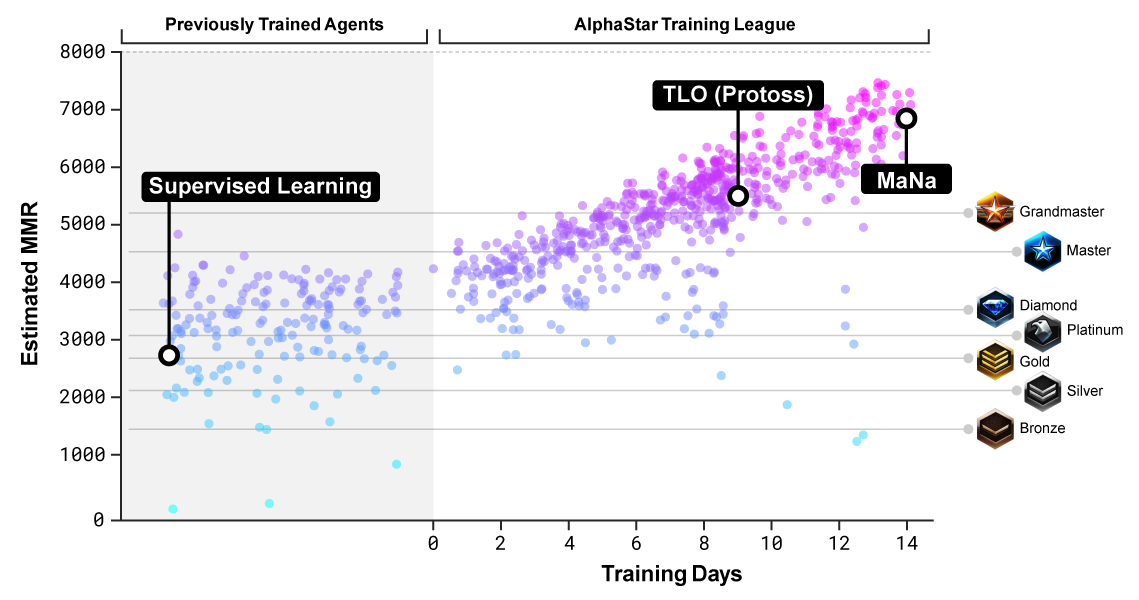
首先基于暴雪公布的历史天梯游戏数据,采用监督学习训练出V0版本模型(模拟玩家微操和宏观操作)。此agent已经可以在95%的对局中击败elite级别computer,对应人类玩家中天梯级别约为黄金。

引入了AlphaStar League概念,这是一个模拟天梯的联赛机制。从原始的V0版本agent开始,进行多轮迭代,每个竞争者agent分别和其他竞争者agent竞赛。在每轮迭代中,新竞争者被分裂复制,原始竞争者被冻结。可以调整竞争者间比赛的概率以及当前参与竞争者agent的超参数以实现在提升难度的同时保证多样性。通过强化学习基于和其他竞争者的比赛结果训练agent的参数。最终的agent通过在整个league中基于Nash分布无放回采样获得。
该策略基于population-based RL和mult-agent RL,使得在不断探索决策空间的同时,还能保证每个agent既可以在和最强策略的对战中表现良好,又不会忘记如何战胜早期对手。
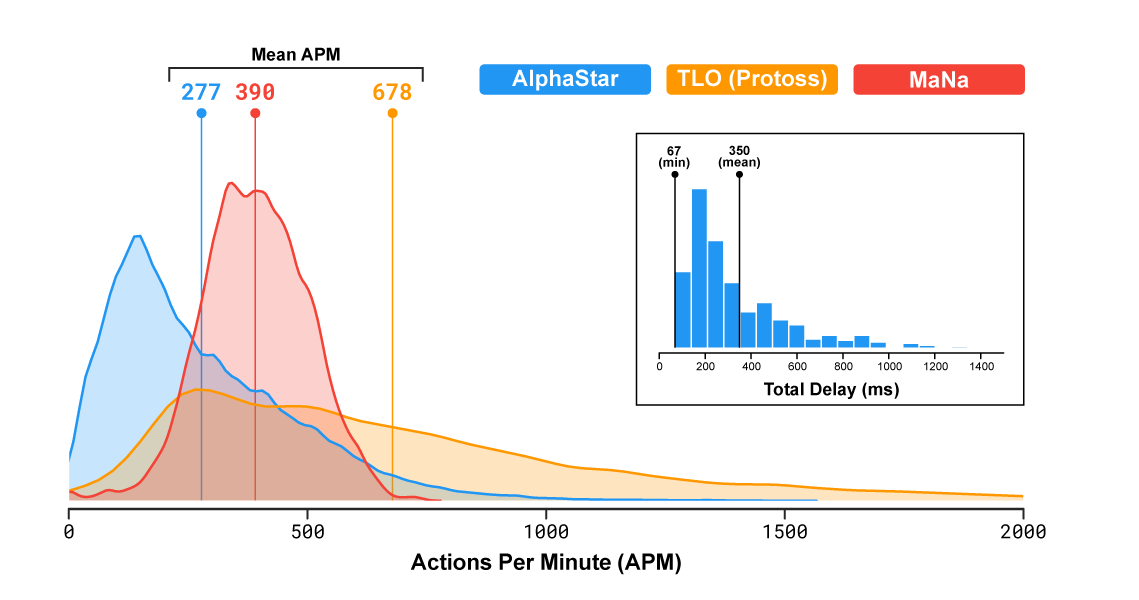
为了保证多样性,每个agent的训练目标不同,例如一个agent需要击败某个特定agent;另一个agent需要通过建造更多的某种特定单元来击败所有其他竞争者。
训练模型为包含经验回放,self-imitation learning和policy distillation的off-policy actor-critic RL算法
训练持续了14天,每个agent训练使用了16块TPU,每个agent进行了相当于200年的实时游戏过程
agent的平均APM 280
文中提到他们训练了两版agent,分别是可以看到全地图的版本和需要移动camera的版本,对比结果如下图:
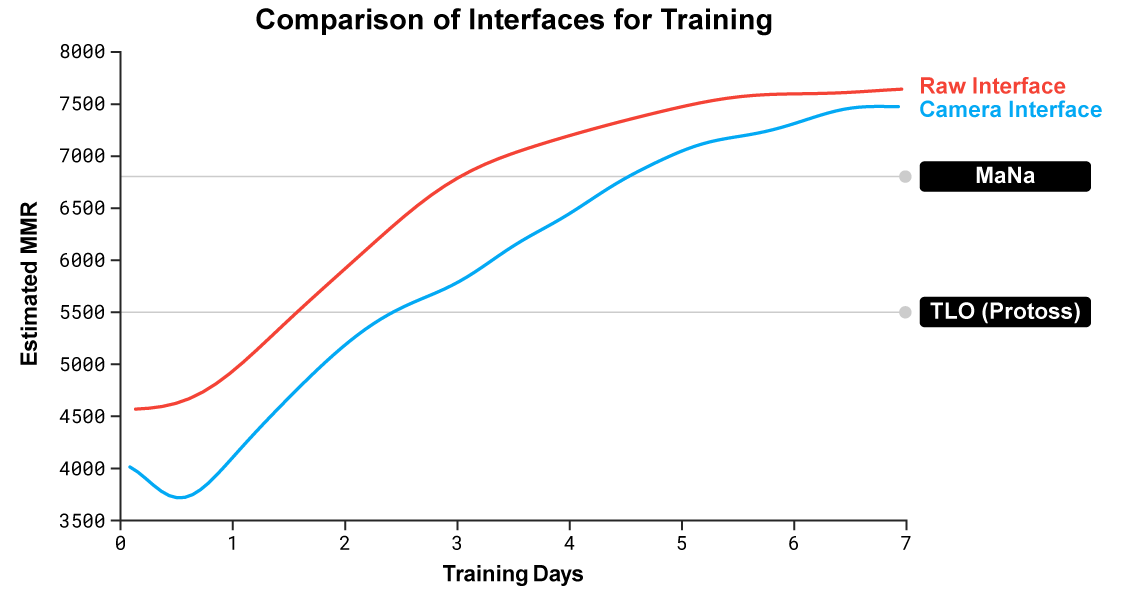
结果表明camera移动的劣势随着训练的推进在逐渐缩小。
后续deepmind会发布详细技术细节文档,持续关注。